#352 — April 22, 2020 |
💬 We've got a neat bonus for you this week at the bottom of the issue 🙂 |
Postgres Weekly |
|
|
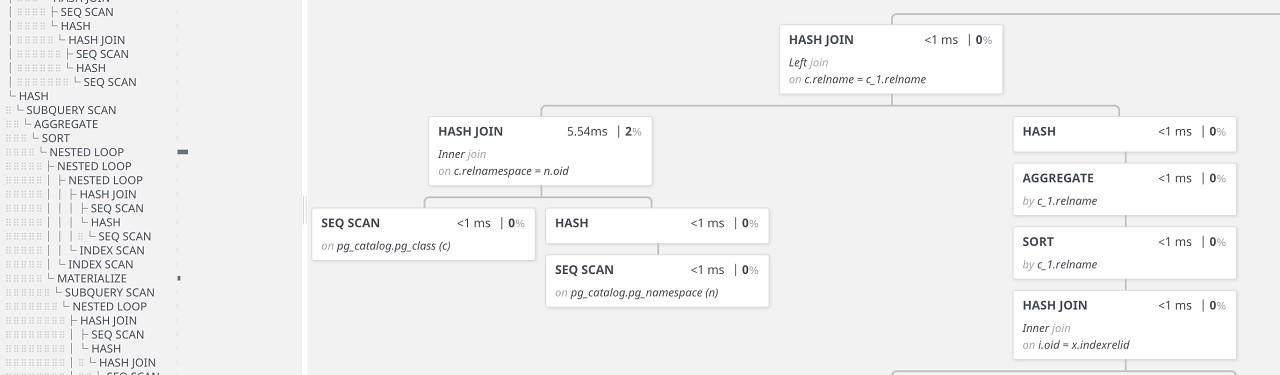
Postgres Explain Visualizer 2: A Vue.js Component to Show Execution Plans — Less a standalone tool and something you’d use when building your own Postgres tooling. There is, however, a demo here. The output is really nifty. Dalibo |
|
Insert-Only Tables To Be Autovacuumed in Postgres 13 (But Why?) — Autovacuuming clears up dead tuples that are often left when updating or deleting data from tables, so why is autovacuuming for append-only tables a big deal in Postgres 13? Laurenz explains. Laurenz Albe |

Faster CI/CD for All Your Software Projects Using Buildkite — See how Shopify scaled from 300 to 1800 engineers while keeping their build times under 5 minutes. Buildkite sponsor |
|
Full Text Search in Milliseconds with Rails and Postgres — If you’ve never played with full text search with Postgres and Rails, this is a fine place to start. It covers Leigh Halliday |
|
An Easy Postgres 12 and pgAdmin 4 Setup with Docker — Docker provides an easy and loosely coupled way to get things set up in a development environment. Jonathan S. Katz |
|
Is There a Limit on Number of Partitions Handled by Postgres? — Sort of, but you’d really have to be going at it to stretch Postgres 12’s capabilities in this area. Denish Patel |
|
Where Do My Postgres Settings Come From? — A nice visual look at how parameters and settings cascade or override each other. My DBA Notebook |
|
Identify Slow-Running PostgreSQL Queries Quickly in Datadog — Improve PostgreSQL performance by visualizing and identifying errors fast using granular, out-of-the-box dashboards in Datadog. Datadog sponsor |
|
Replicate Multiple Postgres Servers to a Single MongoDB Server using Logical Decoding Output Plugin David Zhang |
|
An Overview of the JOIN Methods in Postgres Kumar Rajeev Rastogi |
|

If you enjoyed this interview, Luca actually gave some more detailed answers in the full interview which you can read here. |