AWS Database Blog
Enable near real-time notifications from Amazon Aurora PostgreSQL by using database triggers, AWS Lambda, and Amazon SNS
In this post, we show you how to push a database DML (Data Manipulation Language) event from an Amazon Aurora PostgreSQL-Compatible Edition table out to downstream applications, by using a PostgreSQL database trigger, an AWS Lambda, and Amazon Simple Notification Service (Amazon SNS).
Aurora PostgreSQL is a PostgreSQL-compatible relational database built for the cloud that combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open-source databases.
You may need to notify downstream applications when there is a content update made to your relational database tables. This update could be in the form of an insert, update, or delete statement on the table, which needs to be relayed in real time to a Lambda function. With the support for Aurora PostgreSQL database triggers and their integration with Lambda, you can now call a downstream Lambda function in near-real-time whenever data manipulation is performed on the source database. For example, a new customer onboarding application might involve an insert of a new customer row into a database table. This customer lifecycle event might need to send a welcome email, or perform some other back office workflow.
You can also use the solution presented in this post with Amazon Relational Database Service (Amazon RDS) for PostgreSQL and Amazon Aurora MySQL-Compatible Edition.
Solution overview
The following diagram illustrates the solution architecture.

This architecture involves the following components:
- A single database DML transaction to start the event chain – The event can be any database table insert, update, or delete, which invokes a corresponding database trigger.
- An Aurora PostgreSQL table trigger – The trigger invokes a custom PL/pgSQL trigger function that makes a call to a consuming Lambda function.
- A target Lambda function consumer of the database trigger – The Lambda function receives the newly inserted row from the database in its input argument. Then it publishes this to an SNS topic.
- A target SNS topic – This topic is the recipient of either a summary (row key only) or the detailed row.
- An SNS topic subscription – You can use this subscription to deliver notifications to the downstream actors (applications, Operations teams, and email inboxes).
We walk you through the following configuration steps:
- Create Amazon Virtual Private Cloud (Amazon VPC) endpoints exposed inside the VPC, for Amazon SNS and the Lambda function.
- Create an SNS topic and subscription.
- Create a custom AWS Identity and Access Management (IAM) role for Lambda.
- Create a database event-handling Lambda function launched in the same VPC (subnet).
- Create an Amazon RDS IAM role.
- Configure the Aurora PostgreSQL database.
Example use case
In our scenario, we assume we have different customer management applications, adding (inserting) different customer management business events into a relational business events table that is hosted on an Aurora PostgreSQL database.
The customer_business_events table records data from different applications, such as customer-onboard-app, customer-subscription-app, customer-payment-app, and customer-complaint-app. It records the customer in question (customer_reference_id), the category of the problem, and the reason, error, or exception (exception_reason) of the problem. The born-on business event timestamp is recorded in the event_timestamp column.
You can create the table with the following code:

The following are some examples of the insert statement that populates the customer_business_events table:
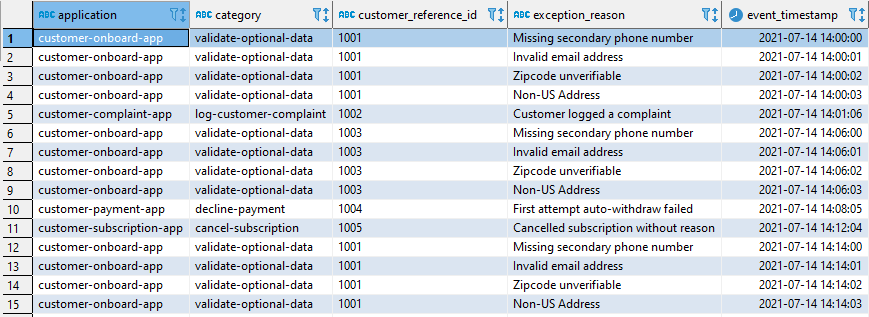
Our goal is to have this table, upon insert (or update or delete), automatically invoke an event-processing function outside of the database to notify the Customer Relationship Operations team of this event for corresponding actions.
Prerequisites
This post assumes that you have an Aurora PostgreSQL (version 11.9 or above) cluster set up. For more information, see Creating an Amazon Aurora DB Cluster.
You can also use Amazon RDS for PostgreSQL (versions 12.6+, 13.2+, or 14.1+) instead of Aurora PostgreSQL.
Create VPC endpoints
We create two VPC endpoints to make our service access local to our VPC (in our private subnets), one for Amazon SNS and the other for Lambda function. This is opposed to having them go through the public internet. For instructions, refer to Create a VPC endpoint service configuration for interface endpoints. The following screenshot shows our endpoints.

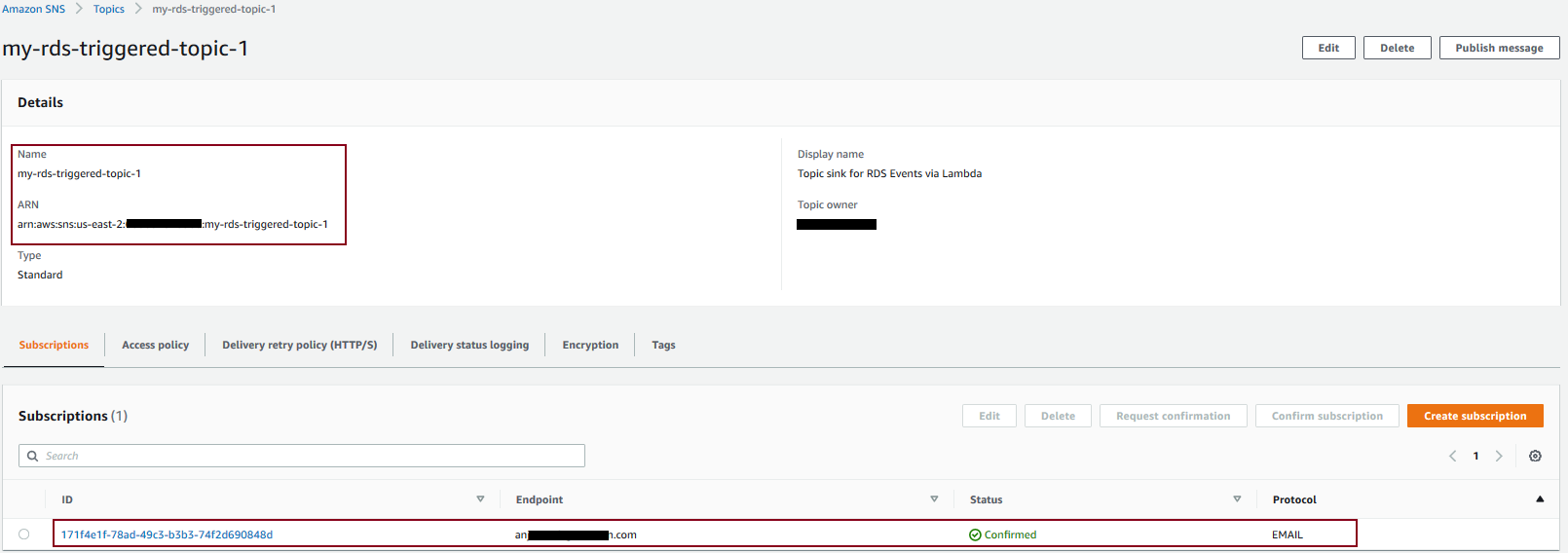
Create an SNS topic and SNS topic subscription
We create the SNS topic my-rds-triggered-topic-1 and corresponding subscription for our Operations team’s email recipients, as shown in the following screenshot.
Create a Lambda IAM execution role
For this example, we set up a custom IAM execution role called MyRdsTriggeredLambdaExecutionRole for Lambda. For instructions, refer to Creating a role to delegate permissions to an AWS service. The role has three policies:
- An AWS managed policy for permissions to run the Lambda function in a VPC, called
arn:aws:iam::aws:policy/service-role/AWSLambdaVPCAccessExecutionRole. - A custom policy to be able to publish to our SNS topic, called
MyRdsTriggeredTopicWriterPolicy. See the following code:
- A custom policy (
MyBasicLambdaExecutionRolePolicy) with basic permissions to run the Lambda function (such as access to Amazon CloudWatch Logs). See the following code:
Create a Lambda function
We create the function my_rds_triggered_topic_writer launched in the same VPC (subnet). For more information, refer to Configuring a Lambda function to access resources in a VPC.
When we create our Lambda function, we set up a few key configurations:
- Lambda function role – We attach the custom role we created.
- Amazon VPC – Because our Aurora PostgreSQL instance is inside a VPC, as is typically the case, we host our Lambda function inside our VPC.
- Environment variable for the SNS topic ARN – We add the environment variable
ENV_TOPIC_ARNwith the valuearn:aws:sns:us-east-2:123456789100:my-rds-triggered-topic-1, which points to the ARN of the target SNS topic. - Lambda function code – We have the following as the source code for the Lambda function:
The code reads the Amazon RDS JSON event payload (a single inserted row), and prints this out. Then it publishes the result to an SNS topic.
Create an Amazon RDS IAM role
For this example, we set up a custom role (MyRdsLambdaExecutorPolicyRole) to associate with our RDS instance. This includes a policy with permissions to invoke our Lambda function. See the following code:
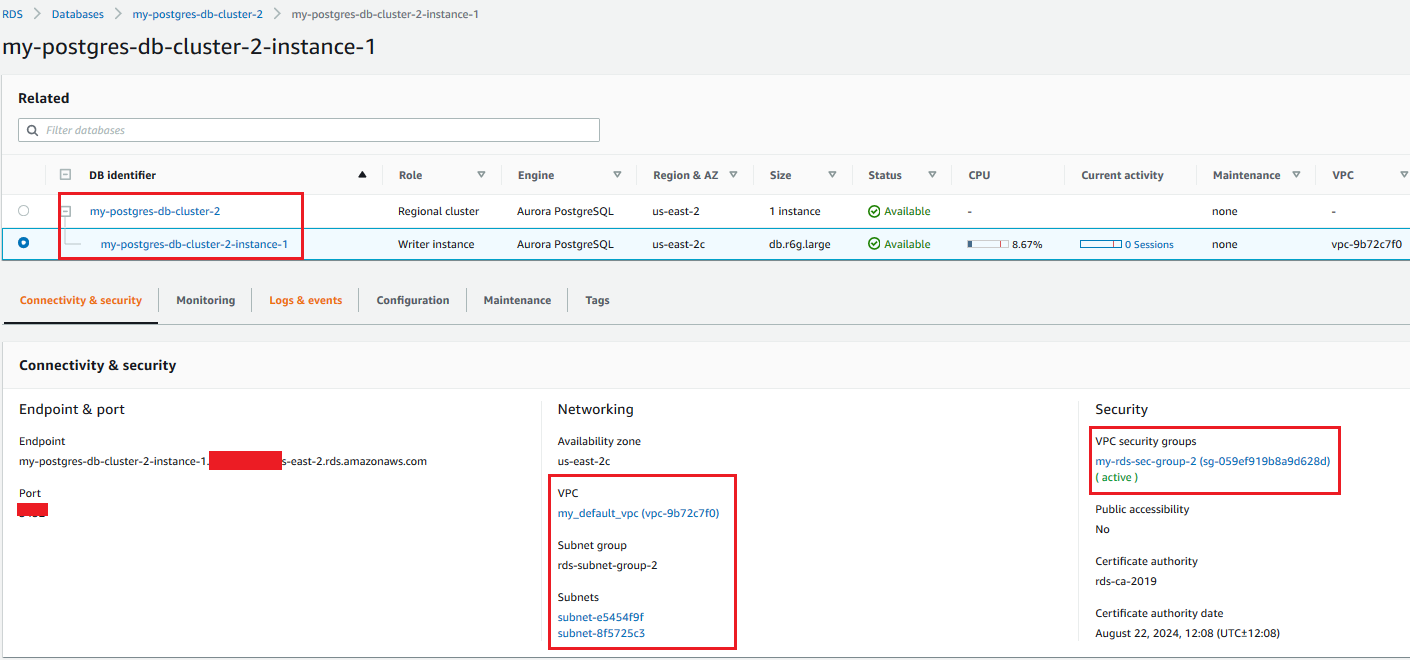
Create an Aurora PostgreSQL database
We set up our PostgreSQL database (Aurora for PostgreSQL v12.6, in our case) and launch the cluster inside our VPC, as highlighted in the following screenshot.
Install PostgreSQL extensions
We install the aws_lambda extension as shown in the following code. When you run the create extension command, that two additional schemas are created. We use the utilities inside these two schemas to invoke our Lambda function.
To establish connection to the Aurora PostgreSQL database you can use your preferred client tool as long as it has connectivity to the VPC. We used DBeaver tool to connect to the database.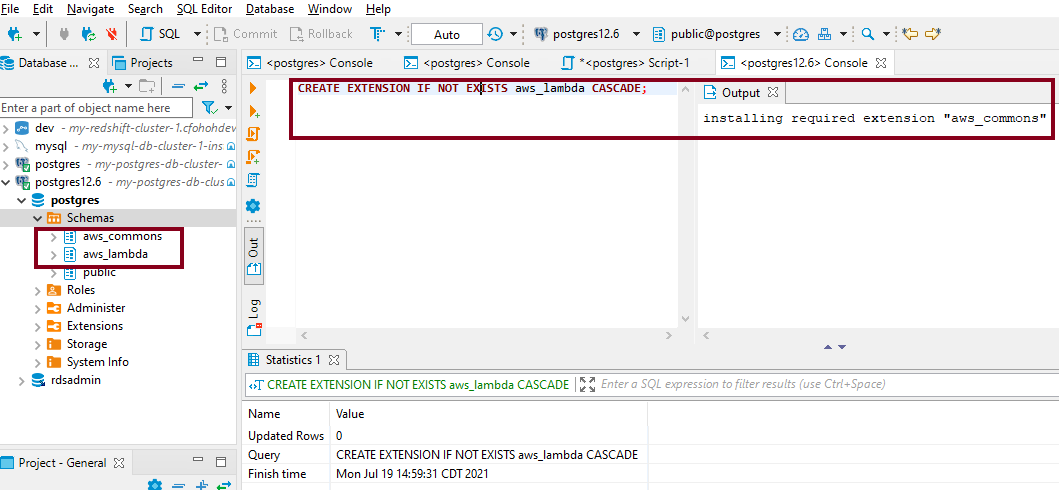
PostgreSQL trigger function and JSON utility function
We use a utility function to convert tabular row data to JSON for convenience, as shown in the following code:
We use a trigger function to actually make the Lambda function call, as shown in the following code:
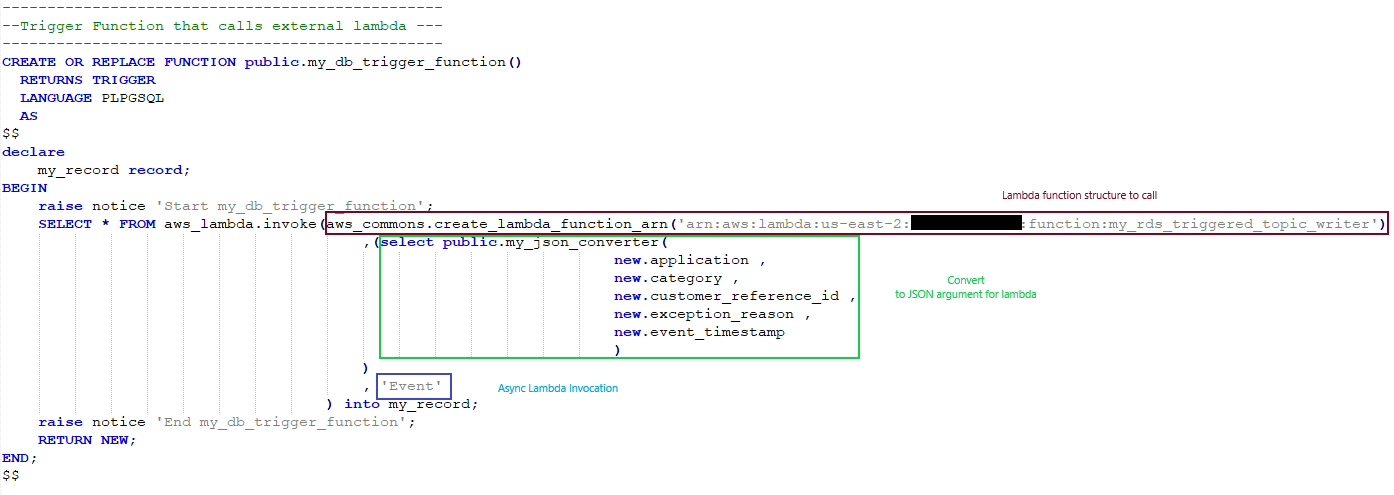
The create_lambda_function_arn creates a Lambda function ARN structure that is compatible with the invoke API call. Because we don’t need a response from the Lambda function into Aurora PostgreSQL, we choose to make an asynchronous call (Event) to the Lambda function without returning a response from Lambda function. For more information, refer to Example: Asynchronous (Event) invocation of Lambda functions.
PostgreSQL trigger
We tie the trigger function to the after-insert trigger on the customer_business_events table, as shown in the following code:

Test the solution
To test the solution, we insert a new row into the customer_business_events table:
We can validate the insert via the following query:
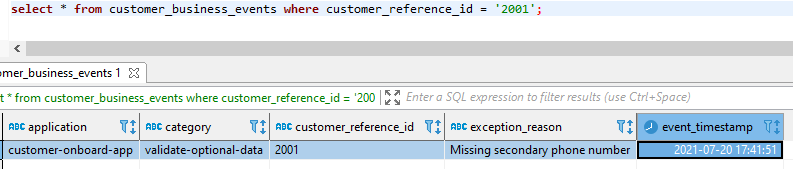
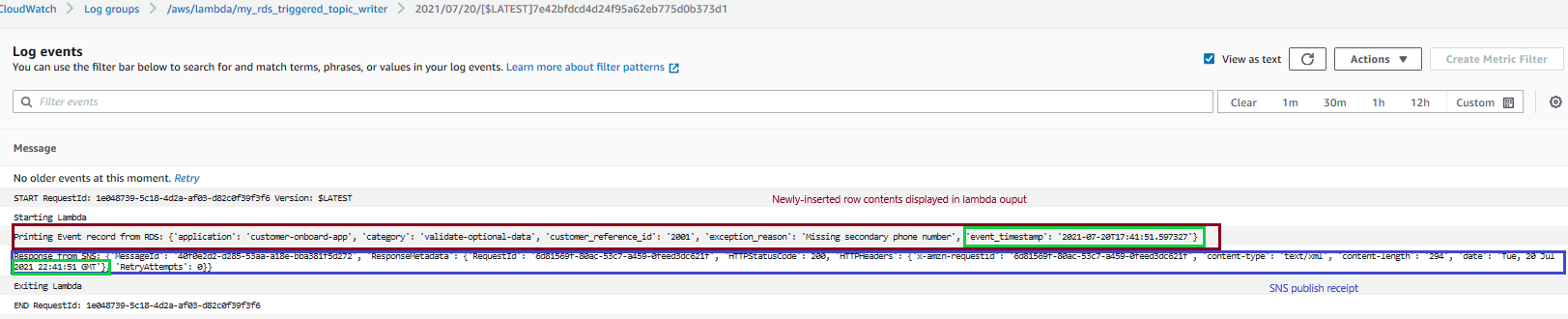
This invokes the trigger on the customer_business_events table, which in turn invokes the Lambda function with an output in the CloudWatch logs. In the following screenshot, the output shows the event payload (red). The timestamp, in green, captures the inserted time of the row in the database table (call to now()). Finally, it publishes the result to an SNS topic with the messageID returned in the response (in blue).
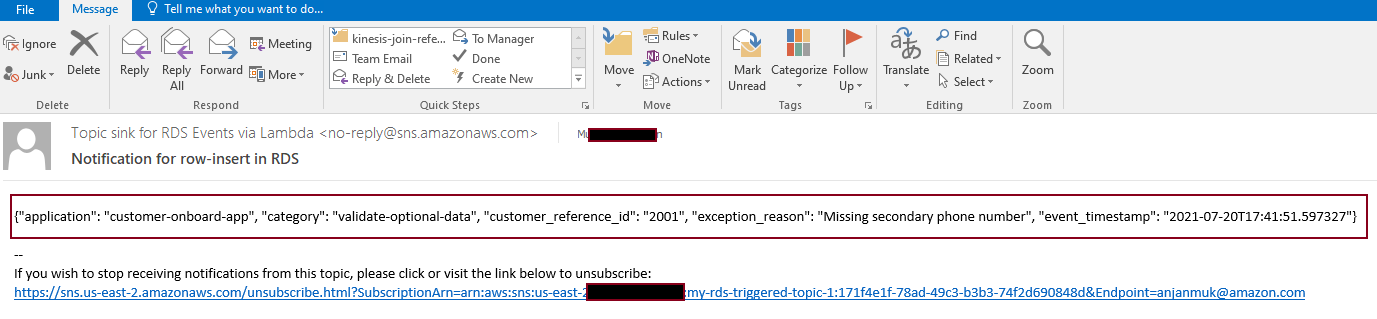
The corresponding email notification delivered via the topic subscription is as follows.
Troubleshooting
If your function code raises an error, Lambda generates a JSON representation of the error. For more information, refer to AWS Lambda function errors in Python.
Considerations
This solution is useful when you want near-real-time latency between a row insert (or update or delete), and the corresponding downstream notification. This might be the case for critical events. Although the example use case referenced in this post is a business events table, this approach isn’t limited to just business events. In fact, any data hosted in an RDS for PostgreSQL or an Aurora PostgreSQL table is a candidate for this approach. However, you should take the following considerations into account when using this approach:
- Querying the table to find recent events is not possible. For example, the table doesn’t contain a last system-change-datetime column. Additionally, querying a table can’t account for deleted events.
- The table has periods of OLTP inactivity as well.
- This post references a FOR EACH ROW trigger, which is triggered one time for every row that is inserted (or updated or deleted). This may cause a small but noticeable performance penalty on the database cluster, for tables with high volumes of transactions.
- Using a synchronous (request response) call to the Lambda function can impact database performance, because the trigger has to wait for the function response to return. This post uses the asynchronous approach to optimize latency. For more information about Lambda function invocation types, refer to Invoking an AWS Lambda function from an RDS for PostgreSQL DB instance.
- High bursts of transactions against the database table result in an equivalent number of Lambda function invocations, which may breach the concurrency limits (Region-specific) of the function, causing possible throttling. Therefore, make sure that the transactions per second on the source table are under the Lambda concurrency limits (especially for FOR EACH ROW triggers). For more information, refer to Lambda function scaling.
- This framework uses Amazon SNS as one of its steps to relay the content downstream. There is a 256 KB limit on a single Amazon SNS message payload. To mitigate this, you should populate the message body with just the essential data, such as IDs, keys, and a few selected attributes, to reduce the payload size. For information pertaining to publishing large messages, refer to Publishing large messages with Amazon SNS and Amazon S3. Additionally, refer to Amazon Simple Notification Service endpoints and quotas for more about quotas and limits.
Conclusion
In this post, we showed how you can invoke a Lambda function from a database trigger whenever a DML operation occurs on your source Aurora PostgreSQL table. Additionally, we showed how to integrate this Lambda function with an SNS topic. This allows you to notify downstream applications, in real time, when critical business updates are made to your relational database tables.
Although this post specifically uses Amazon RDS for PostgreSQL and Aurora for PostgreSQL, you can also extend it to Amazon RDS for MySQL and Amazon Aurora MySQL-Compatible Edition. For more information, refer to Invoking a Lambda function from an Amazon Aurora MySQL DB cluster.
About the Authors
 Wajid Ali Mir is a Database Consultant with the Professional Services team at Amazon Web Services. He works as database migration specialist to help Amazon customers to migrate their on-premises database environment to AWS cloud database solutions.
Wajid Ali Mir is a Database Consultant with the Professional Services team at Amazon Web Services. He works as database migration specialist to help Amazon customers to migrate their on-premises database environment to AWS cloud database solutions.
 Anjan Mukherjee is a Data Lake Architect at AWS, specializing in big data and analytics solutions. He helps customers build scalable, reliable, secure and high-performance applications on the AWS platform.
Anjan Mukherjee is a Data Lake Architect at AWS, specializing in big data and analytics solutions. He helps customers build scalable, reliable, secure and high-performance applications on the AWS platform.