AWS Database Blog
Best practices for Amazon RDS for PostgreSQL major upgrades and replicas
When Amazon Relational Database Service (Amazon RDS) supports a new version of a database engine, you can upgrade your DB instances to the new version. Latest engine versions released by PostgreSQL community contain fixes for bugs, security issues, and data corruption problems. Generally, Amazon RDS aims to support new engine versions shortly after their availability. You also must upgrade your Amazon RDS for PostgreSQL instances when a particular version is no longer supported.
There are two kinds of upgrades for PostgreSQL DB instances: major version upgrades and minor version upgrades. For the scope of this post, we focus on major version upgrades, and the impact on replicas when the primary is upgraded.
Upgrading a primary replica in Amazon RDS for PostgreSQL
During major version upgrades, Amazon RDS for PostgreSQL upgrades all your in-Region read replicas along with the upgrade of your primary database instance by default. You can choose to skip upgrading the replica instance by either promoting or deleting it prior to upgrade.
In this post, we go over both methods of major version upgrades for a primary and replica instance setup in Amazon RDS for PostgreSQL. We also touch upon the benefits of either method and what general considerations and best practices to follow to get the best of both worlds.
Upgrading replicas concurrently
When concurrently upgrading replicas, the primary and all if its replicas in the same Region are upgraded to the new major version. When you submit the modify request for the major version change on the primary, the replica is marked to be upgraded as well. The replica is synchronized with the primary after the latter is upgraded to complete the overall upgrade process for the instances. This is the default behavior offered by Amazon RDS for PostgreSQL.
The following diagram illustrates a concurrent replica upgrade.

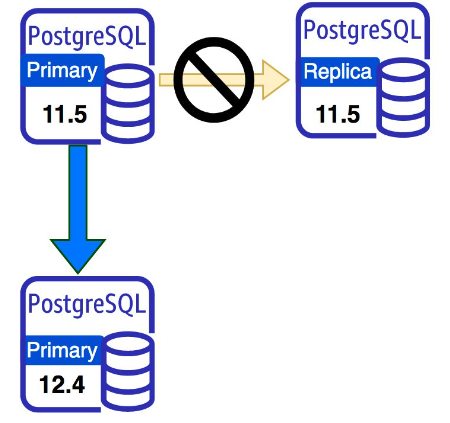
Promoting or deleting replicas
In this approach, you have to first promote the replica, making it a standalone instance, or alternatively, delete the read replica. Then you can upgrade the primary instance to the newer major version.
The following diagram illustrates promoting the read replica before upgrading the primary.
Choosing an approach when planning an upgrade
In the default approach of concurrently upgrading the instances, when you submit a request to perform a major version upgrade of your primary instance, the replicas are simultaneously upgraded. Your primary and replica instances are placed in an upgrading lifecycle state. All in-Region read replicas wait for the upgrade process on the primary to finish, after which all replicas start to undergo the upgrade concurrently. The number of replicas the primary instance has doesn’t make a difference to the overall upgrade completion time because they’re upgraded in parallel. The time taken for a standalone primary instance with no replica to complete is the shortest. Because the replicas are upgraded in parallel, the time to upgrade an instance with a single replica or multiple replicas is almost the same.
If you choose to delete the replica before upgrading the primary instance, for large databases, recreation could take a long time. When creating a replica, Amazon RDS for PostgreSQL takes a snapshot of the primary instance and restores it. The larger the instance size and the more objects in the database, the more time it could take to restore the snapshot.
With this in mind, concurrent upgrades has an advantage: you don’t have the hassle of restoring snapshots to create new replicas and wait for hours, days, or even weeks in some cases. All the instances are upgraded at once, and are available at the same time, without any further waiting.
When deciding on an approach, there’s a trade-off. You should plan beforehand if you want to promote or delete your pre-existing replicas prior to a primary upgrade. This depends on the amount of downtime your application can handle at a stretch. During concurrent upgrades, your primary and all in-Region replicas are unavailable until the upgrade process on all of them is complete. Upgrading the replicas along with the primary can have extended downtime for the overall system. Therefore, you can choose to promote the replicas or delete them for the least downtime.
If you choose to promote a read replica prior to an upgrade, you can continue to use it as a standalone instance to serve read traffic while the original primary undergoes the upgrade. However, if your application requires replica instances to serve traffic, when the upgrade is complete, the primary instance needs to serve all the application traffic until the new replicas are ready. In either case, because a major version upgrade is an irreversible change, we recommend extensive testing prior to upgrading your production instances.
Cross-Region replicas are not upgraded with the primary and display the message Streaming replication has stopped. The replication status shows as Error. The following is an example showing a cross-Region setup.
The primary is in Region eu-west-1.
![]()
The replica is in Region eu-west-2.
![]()
After the primary is upgraded, the replica shows signs of broken replication. The following screenshot lists recent events.

The following screenshot shows replication details.

Best practices Amazon RDS for PostgreSQL major version upgrades
In this section, we discuss some best practices and considerations when planning a major version upgrade.
Amazon RDS for PostgreSQL uses the native pg_upgrade utility to upgrade the instance to a new major version. This process involves downtime and should be done within a preferred maintenance window only. We recommend you plan a scheduled maintenance window for this upgrade activity, preferably when your database is being queried the least. For more information, see Upgrading the PostgreSQL DB engine for Amazon RDS.
If a replica can’t be synchronized with its primary during the upgrade, it’s placed in the INCOMPATIBLE RESTORE state. You’re notified via an event on the instance. Because this state is a terminal state, you have to delete and recreate the replica after the upgrade.
To make sure you can safely restore to the previous version if anything fails, it’s always recommended to take a manual snapshot before upgrading your RDS for PostgreSQL instance major version. Amazon RDS for PostgreSQL automatically takes a snapshot before the upgrade if automated backups are enabled.
Be sure to perform extensive testing before upgrading your RDS for PostgreSQL instance version. The testing, apart from upgrade times, also gives you a good idea about the application compatibility and the features or changes your application might have to adapt to in the new major version. To create an instance with the same data as your production instance, you could do the following:
- Restore a snapshot of your instance, upgrade it to the new version, and use this for testing
- Create a read replica, promote it to a standalone instance, upgrade it to the new major version, and perform your testing on it
Make sure you have a properly sized instance class with enough memory available for the upgrade. The upgrade process requires memory, and it might fail if that’s insufficient. Monitor the FreeableMemory Amazon CloudWatch metric before performing the upgrade. Scale accordingly to a bigger instance class before the upgrade.
As a part of an upgrade request, if using a custom parameter group at the primary engine version, you must provide a target version parameter group. For read replicas, if you have custom parameters set, Amazon RDS for PostgreSQL creates a new parameter group of the target version retaining those settings. If any of your instances use a default parameter group at the primary version, the default one for the target version is applied post-upgrade automatically.
It’s recommended to make sure pre-upgrade that the custom parameters are compatible with the target version to prevent any parameter-related issues and ensure a seamless upgrade. Post-upgrade, if the instance needs to be rebooted to apply the parameter group changes, the instance’s parameter group status shows as pending-reboot.
For any automatically triggered major version upgrade such as a replica upgrade, a default option group for the target version is created. This starts with the prefix default. This has no impact on the instance because RDS PostgreSQL doesn’t use options and option groups.
The following image shows the modification (upgrading) of the instance version from 11.5 to 12.4, which involved changing the parameter from a custom pg11 group to a default default.postgres12.

You still get the option to apply the version modification (upgrade) immediately, or in the next maintenance window. Choose accordingly, because upgrade operations causes downtime. The following screenshot shows the option on the console.

If the upgrade on the primary fails due to pre-check failure, the replicas are also not upgraded. The pre-check procedure checks all potential incompatible conditions across all databases in the instance. If the pre-check encounters an issue, check the log pg_upgrade_precheck.log and fix it before trying the upgrade again.
While the upgrade is happening, you can see the primary and all its replicas in Upgrading status until they are all upgraded.

However, the console has a slight delay in updating the status of the instance. To understand and identify the true downtime, and not let the applications wait for longer to reconnect, you can run the following query in a script:
You can use this command to connect to the DB instance and return back the postmaster uptime. You should replace the port as well, if you’re not using the default Postgres port 5432. The -w option specifies no password because we already have .pgpass file in our example. This is to avoid the hassle of typing the password repeatedly while checking the DB instance state in a script.
As soon as the script returns a value, that means the engine is up and running, and you can resume your application without waiting for the console update delay. This should be run for all the instances that are upgraded in the process.
After the instances are successfully upgraded, to achieve optimal performance, we recommend you run Analyze to refresh the statistics used by the planner.
PostgreSQL extensions are not upgraded by pg_upgrade, and you must upgrade all extensions manually after the upgrade.
Enter the following code before the upgrade:
Enter the following code after the upgrade:
Summary
In this post, we discussed the new default method to upgrade replicas concurrently during a major version upgrade. If you don’t want to upgrade replicas along with the primary, you should delete or promote them before upgrading the primary. Which method to choose is a trade-off that depends on primary downtime and replica availability. The new method of concurrent replica upgrades only impacts in-Region replicas. Cross-Region replicas are in a replication error state after the primary is promoted. Review the best practices for a smooth upgrade activity.
For more information about upgrading an Amazon RDS for PostgreSQL major version, see Upgrading the PostgreSQL DB engine for Amazon RDS.
If you have any questions or suggestions about this post, feel free to leave a comment. We hope the information we shared helps!
About the Authors
 Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
Divya Sharma is a Database Specialist Solutions architect at AWS, focusing on RDS/Aurora PostgreSQL. She has helped multiple enterprise customers move their databases to AWS, providing assistance on PostgreSQL performance and best practices.
 Anisha Cherodian is a Software Development Engineer with AWS RDS PostgreSQL team. She has worked on designing and developing various customer facing features such as major version upgrades with read replicas.
Anisha Cherodian is a Software Development Engineer with AWS RDS PostgreSQL team. She has worked on designing and developing various customer facing features such as major version upgrades with read replicas.